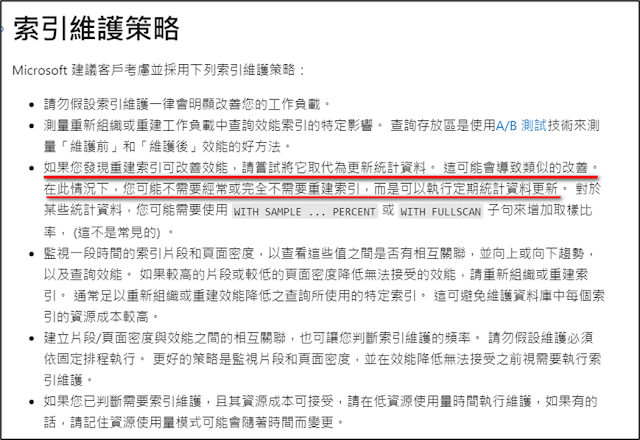
我仍記得在好多年前在某公司擔任AP兼DBA,有次在手動清除一些TABLE的資料時,因為TABLE太多了沒有去檢查這些TABLE的筆數。就直接執行
Delete TABLE1 where 日期<’xxxx/xx/xx’
Delete TABLE2 where 日期<’xxxx/xx/xx’
….
Delete TABLEn where 日期<’xxxx/xx/xx’
然後放著讓它跑,就去做別的事了…
大約過了幾小時吧,接到電話說系統卡住了都跑不出來,上去 DB 看後發現是我剛才的 delete 跑到了某個大 TABLE 而 delete 了很久,鎖住了許多 query。為了怕影響系統的運作,當時想說就把 delete 的作業暫停應該就好了。
在我 kill 了delete之後,再問系統人員還是說卡住….。
我再進 DB 看,發現原本的 delete 的 session 還在,並沒有立即中止,sp_who 看 status 欄位顯示是 rollback。再嘗試多次的 kill,那個 rollback 的 session 仍然無法中止。
隨著電話不斷的來,長官也紛紛跑來關切;google了一下,都說 rollback 是無法中止的,只能等它自己跑完………。當下真的臉都綠了,只能不斷的抱歉,心驚膽顫的過了一兩個小時…終於 rollback 結束了…
......
.....
那次出了一次大包,印象非常深刻。
如今,我成了專職的 DBA了,對於所謂的系統結構、交易、rollback…等問題也有了比較清楚的認識。
去年曾經有朋友問過我 rollback 如何中止,今天去拜訪客戶時也被問到相同的問題。又讓我想起這慘痛的經歷,所以就想和大家分享一下如何中止 rollback。
~~~讓我們回到主題~~~
問題:SQL
SERVER 有辦法中止rollback嗎?
答案:可以,但rollback所在DB交易資料不一致的風險自負。
情境模擬
首先建立一個資料庫及TABLE
create database TestRollback
go
use TestRollback
go
create table test0221(c1 int identity,c2 char(1024))
go
接著我做一段迴圈讓它不斷去insert資料
declare @x int = 1
begin tran
while (@x<10000000)
begin
insert into test0221 values('aaaaaaaaaaaaaaaaaaaaaa')
set @x+=1
print @x
end
當它跑到某個階段後,將這個session kill
用sp_who2看,可以看到它正在rollback
以上是簡單的模擬正在rollback情況,以這個例子來說,當rollback發生時,原本已經insert進去的資料系統會自動delete。
Rollback發生時會保留rollback前所擁有的鎖,一個基本的判斷原則是如果你的session目前是table lock,那麼rollback期間也會是table lock,例如我最前面的經歷,因為我的delete鎖住其它人,那麼當這個delete被rollback時,仍然會鎖住其它人。
停止rollback的方法
要停止rollback的方法步驟如下:
一、
alter database DBNAME set offline with
rollback immediate。
二、
使用sp_who2檢查status=rollback的連線,是不是只剩下你要中止rollback的連線。
三、
shutdown with nowait,強制將SQL
SERVER關閉。
四、
從OS層級刪除rollback所在DB的log file。
五、
啟動SQL SERVER,rollback所在DB由於沒有log file,無法開始recovery,將會被置於「復原暫止recovery pending」的狀態。
六、
Alter database DBNAME set emergency,將rollback所在DB設為「緊急模式 emergency mode」,emergency mode可以解釋為「bypass recovery」,它會跳過recovery步驟,並允許使用者去存取資料庫。
(1)
Dbcc checkdb(‘DBNAME’,repair_allow_data_loss)
(2)
Alter database DBNAME rebuild log on(
Name=’xxxx_log’,
Filename=’c:\xxxx\xxxx\xxxx.ldf
)
八、
alter database DBNAME set multi_user
實作
為了最大程度的降低交易資料不一致的損害,首先執行:
alter database Testrollback set offline with rollback immediate
正在rollback很久的session不會因為這句而中斷,但這句語法它可以先強制關閉其它正常的session,如果有其它交易中的session也會正常的rollback,並拒絕新的連線。
接著使用sp_who2檢查,確認狀態為rollback的連線,僅剩你想要中止的連線。
這個目的是要避免其它交易受波及,並確認交易不一致的風險在掌控的範圍內。
上面確認無誤後,就可以將SQL SERVER 強制關閉,不等rollback完成
接著從OS層級將rollback所在DB的log file刪除
之所以要刪除log file,是由於任何對DB的異動(包含rollback),都會被紀錄在log中。而SQL SERVER啟動時會先讀取每個資料庫的log file然後執行recovery (redo+undo),由於我們是rollback未完成就直接shutdown,如果不刪除log file,在SQL SERVER重新啟動時仍會依照log file的紀錄繼續執行rollback。
所以,要想避免又開始rollback,我們需要把資料庫的交易紀錄檔從OS中刪除,這樣一來由於沒有交易紀錄檔可以參考,所以SQL SERVER啟動時該DB也不會有rollback發生。
接著我們重新啟動SQL SERVER~~
由於沒有交易紀錄檔,該DB將無法開始recovery,SQL SERVER可以正常啟動,但該資料庫將會被標示為「復原暫止
recovery pending」,且無法被讀取。
接著,我們可以將資料庫置於「緊急模式 emergency mode」。
alter database TestRollback set emergency
所謂「緊急模式 emergency
mode」 可以解釋為「bypass recovery」,它要求 SQL SERVER 跳過recovery步驟,並允許使用者去讀取資料庫(read_only)。
這個過程簡單的說就是SQL SERVER找不到DB的log file,無法對這個DB進行recovery,所以DB被SQL
SERVER中止上線。而我們將DB設為緊急模式就是告訴SQL
SERVER這個DB有急用,要求略過recovery的步驟讓DB上線。
進入緊急模式後就可以去讀取資料庫,我們來看看test0221這個TABLE是否有資料?
在執行kill後它開始rollback,rollback動作是參考log file的紀錄逐條做undo,如果你是逐筆insert那麼你可以想像成系統就逐筆delete。
我們前面kill insert時已經insert了44722筆,直到SQL SERVER shutdown,期間會有部份資料已經rollback回去,所以我們現在看到的筆數為44565。
到此時我們已經成功停止了rollback的動作,最後就是去重建DB的交紀紀錄檔讓DB上線即可。
重建交易紀錄檔,建議使用dbcc checkdb來讓系統自動重建交易紀錄檔,並且去修復因遺失log file而造成的系統頁面或系統表的紀錄失真。
接著我們執行dbcc checkdb讓系統重建log file,並修復系統頁面及系統表
從dbcc的返回訊息中,可以看到交易紀錄檔已重建,一些系統頁面的錯誤也己更正。
註:
在這種情況下,執行dbcc checkdb REPAIR_ALLOW_DATA_LOSS將會執行下列幾件事
Ø
跳過損壞的交易紀錄,並儘可能的做recovery。
Ø
建立一個新的交易紀錄檔。
Ø
完整的DBCC CHECKDB (N'DBNAME', REPAIR_ALLOW_DATA_LOSS)指令運行。
Ø
嘗試使DB online。
最後,將資料庫設為正常模式即可
alter database TestRollback set multi_user
結語
要停止rollback,需要強制shutdown SQL SERVER,並刪除log file。會導致SQL SERVER服務中斷,並影響rollback DB交易資料一致性,要特別小心。
另外,使用dbcc checkdb重建交易紀錄檔所需的時間視資料庫大小而定,如果資料庫很大使用dbcc重建交易紀錄檔的時間也會需要一段時間。因此如果真的急著要讓DB上線,可以使用alter
database ….rebuild log去重建LOG file,之後再找時間執行dbcc checkdb去更正系統頁面及系統表。
DBA在kill
session或執行相關維護指令時,真的要特別注意不要掉進rollback的坑。如果不慎掉進去了又急著上線,可以參考這個方法去中止rollback,但DBA必需知道它的影響範圍....。再次強調這是一個應急的方法,如果能允許等待自動rollback結束,建議還是乖乖的等。
若要更深入的理解「中止rollback」背後的機制,建議大家可以去了解交易、交易紀錄(commit/rollback的行為)、SQL 啟動過程(recovery)…等主題。瞭解了之後,掌握它動作的原理,在你中止rollback過程中也比較不會心驚驚。