Begin
同事在測試missing index,建立一個簡單的Heap TABLE,新增了1萬多筆資料,接著執行一句select。本來預期SQL SERVER的執行計劃中應該要出現遺漏索引的建議,但實際上卻沒有。
到底SQL SERVER是如何決定要不要提出遺漏索引建議的?
Background
從SQL SERVER 2005開始,新增了一個遺漏索引的功能,用於提供使用者一個最佳的索引建議,以節省查詢成本。當SQL 語句被執行時,若有遺漏索引則系統會將其資訊將紀錄於下列DMV中。(評估執行計劃所顯示的遺漏索引不會紀錄)
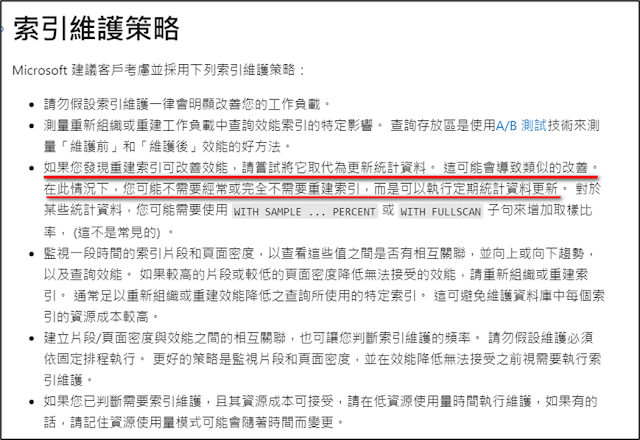
底下是微軟官方對遺漏索引的說明:
Study
上圖中寫道「未針對簡單查詢計劃提出建議」,原文為「Suggestions aren't made for trivial query plans」,它的意思是當執行計劃是一個「簡單查詢計劃」時,不會提供遺漏索引的建議。
註:執行計劃(execution plan)與查詢計劃(query plan)是同義字,兩者意義相同。
~~
那麼,什麼是「簡單的查詢計劃」呢 ..?
我們可以在執行計劃的根節點→屬性→最佳化層級(optimization
level),查看此執行計畫的優化層級是TRIVIAL或FULL。當值為TRIVIAL時,即是所謂簡單查詢計劃。
何謂TRIVIAL及FULL
查詢優化器是基於成本的,所謂的「成本」包含了優化成本+執行成本。我們也不希望優化器花費數分鐘來產生僅需幾秒鐘即可執行完的執行計劃。因此,優化器會避免在優化上花費的時間多於在查詢上節省的時間。故優化的目標並不是探索每一個可能的執行方案來找到最佳的執行計劃。而是快速找到一個已經足夠好的執行計劃。
註:所以有時候我們必須使用查詢提示或計劃指南來手動優化,以產生特定的更好的執行計劃。
優化器有兩個大的優化層級TRIVIAL及FULL (Exploration),其中FULL又可細分為3個階段search
0~2,所以優化器最多會運行4個階段。
每個階段各有其進入條件和終止條件。進入條件意味著可以跳過一個階段;例如search 0在輸入樹中至少需要三個連接表引用,如果少於3個連接,那麼將直接跳過search 0進入search 1。
終止條件有助於確保優化器不會花在優化上的時間超過它節省的時間。如果當前最低計劃成本邊界低於配置值,則搜索將提前終止,並顯示「已找到足夠好的計劃」。

TRIVIAL
前面提到遺漏索引「未針對簡單查詢計劃提出建議」,所謂簡單查詢計劃即是TRIVIAL。因此當執行計劃的最佳化層級是TRIVIAL時,優化器將不會產生遺漏索引的建議。
官方文件及相關資料中並沒有清楚說明什麼樣的情況下會產生TRIVIAL執行計劃,經測試及參考,歸納出下列五點,當同時滿足下列五點時,即會產生一個TRIVIAL執行計劃。反之,則將進入FULL優化階段。
一、
SQL語句中沒有子查詢
二、
SQL語句中沒有join其它table
三、
SQL語句的來源TABLE中沒有任何non-clustered index
四、
估計成本低於Cost Threshold for Parallelism
五、
跟踪旗標8757為off狀態(trace flag 8757用於控制是否跳過TRIVIAL plan)
依上面所說,以本文開頭的例子,若要避開TRIVIAL plan,可以在where條件下加入一個無用的子查詢「and 1=(select 1)」,即會產生FULL plan並產生遺漏索引建議(如下圖)
你也可以將Cost Threshold for Parallelism調整為0,因為任何執行計劃成本必定大於0,所以任何的執行計劃的最佳化層級都將為FULL。當然你也可以使用trace flag 8757跳過TRIVIAL plan。這些有興趣的人可以自行試看看。
系統何時才會產生遺漏索引建議:
一、當最佳化層級為FULL,且發現有更好的索引而TABLE中沒有時。
二、遺漏索引所渉及的相關欄位在SQL語句中沒有發生隱含式轉換。
遺漏索引的建議可信嗎?可否直接依SQLSERVER建議建立遺漏索引?
個人建議對「遺漏索引」抱持審慎懷疑的態度,因為:
一、 遺漏索引所建議的索引鍵,沒有按照索引優化的順序,最好重新審視那些索引鍵欄位的順序。
二、 有時遺漏索引會建議include一些欄位,但SQL Server在建議大量include欄位時,不會對產生的索引大小執行任何成本效益分析。若發現遺漏索引建議的include欄位太多,需審慎斟酌。
三、 遺漏索引的建議,可能會與現存的索引類似,需將遺漏索引與現存索引比對,並儘可能合併索引。
四、在SQL 2008有個bug,遺漏索引會建議一個已經存在的索引,也就是即使你依照遺漏索引建立了,下次SQL語法執行時,系統又建議相同的遺漏索引,而這個遺漏索引其實已經存在於TABLE之中。官方雖稱在SQL 2012解決了,但我在SQL 2019中測試仍然存在。
遺漏索引bug測試,可以參考下列連結
https://www.sqlskills.com/blogs/paul/missing-index-dmvs-bug-that-could-cost-your-sanity/
也可直接使用下列scripts
--建立測試用TABLE,並塞入資料
CREATE UNIQUE CLUSTERED INDEX t1_clus ON t1 (c1);
GO
SET NOCOUNT ON;
GO
INSERT INTO t1 DEFAULT VALUES;
GO 100000
--查詢語句,使用cursor,看執行計畫它有遺漏索引,即使你依照建議建立相同的遺漏索引,下次再執行語法時,它仍然跳出遺漏索引。
DECLARE testcursor CURSOR FOR
SELECT c1 FROM t1
WHERE
c2 BETWEEN 10 AND 1000
AND c3 > 1000;
DECLARE @var BIGINT;
OPEN testcursor;
FETCH NEXT FROM testcursor INTO @var;
WHILE (@@fetch_status <> -1)
BEGIN
--empty body
FETCH NEXT FROM testcursor INTO @var;
END
CLOSE testcursor;
DEALLOCATE testcursor;

遺漏索引何時會清除
依微軟官網所述
註:上圖提到當我們在TABLE建立索引時,會變更資料表的中繼資料。而資料表的中繼資料變更會清除該資料表相關的遺漏索引。因此只要你在該TABLE的任何欄位建立索引,該TABLE的相關遺漏索引都會從遺漏索引清單中移除。
一、SQL SERVER重啟(清除所有遺漏索引)
二、HA failover(清除所有遺漏索引)
三、DB offline(清除該DB所有遺漏索引)
四、Table meta-data變更,亦即針對TABLE結構的變更,包含在TABLE上建立任何索引(清除該TABLE所有遺漏索引)。
五、Index rebuild(清除該TABLE所有遺漏索引)。
End
遺漏索引只有在執行計劃最佳化層級為FULL時,才可能出現。以前一直沒有注意到這個問題,只知道有這個功能。它是一個蠻好用的功能,也確實在SQL語法優化時有很大的幫助,不過系統提出的遺漏索引應審慎懷疑,最好經過評估後再建立。